Statistický soubor má rozsah n, pokud obsahuje právě n jednotek. Například statistickým souborem s rozsahem 10 může být skupinka 10 dětí ze třetí třídy. Jednotliví žáci a žákyně jsou pak jednotky statistického souboru.
Příklady statistických znaků, které nás mohou zajímat: jméno, výška, známka z prvouky. Předpokládejme, že jména dětí z naší skupinky deseti žáků a žákyň jsou: Anna, Eva, Jan, Jan, Jan, Vanesa, Vanesa, Mirka, Tobiáš, Tomáš.
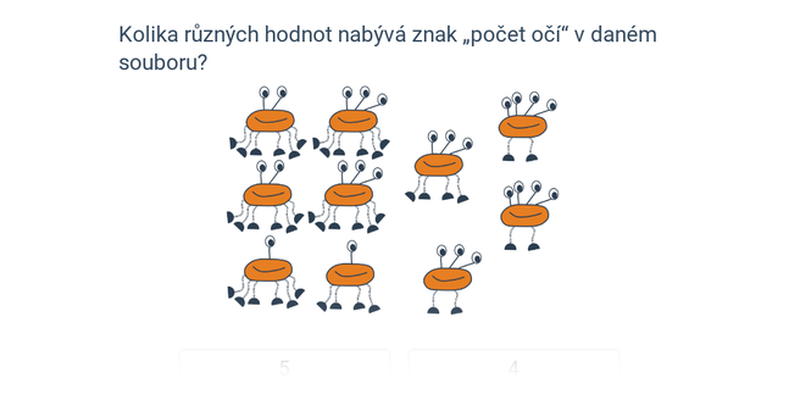
Znak jméno tedy v našem statistickém souboru nabývá sedmi různých hodnot – Anna, Eva, Jan, Vanesa, Mirka, Tobiáš, Tomáš. Některé děti se mohou jmenovat stejně.
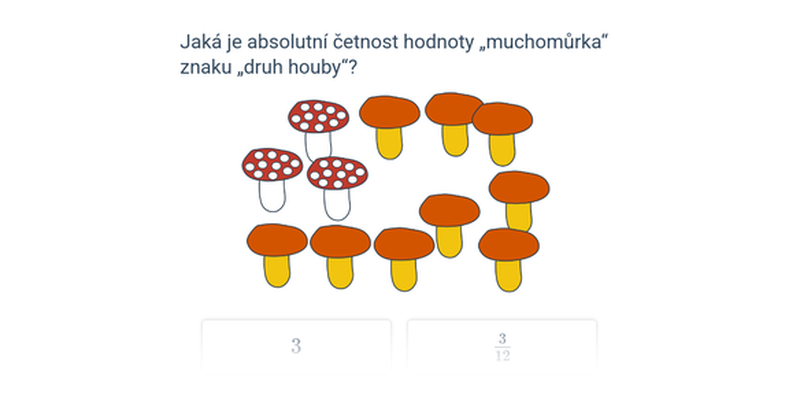
Absolutní četnost hodnoty znaku v daném statistickém souboru je počet jednotek ze statistického souboru, které mají danou hodnotu znaku.
Například absolutní četnost hodnoty „Jan“ znaku jméno je 3, protože ve skupince jsou tři žáci jménem Jan. Absolutní četnost hodnoty „Eva“ znaku jméno je 1.
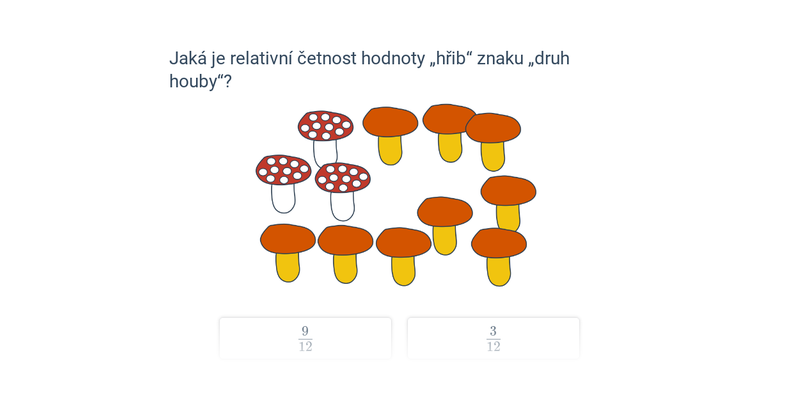
Relativní četnost hodnoty znaku v daném statistickém souboru vypočítáme jako podíl počtu jednotek s danou hodnotou znaku počtem všech jednotek statistického souboru. Také se dá říci, že relativní četnost hodnoty znaku je podíl absolutní četnosti této hodnoty znaku a rozsahu n statistického souboru. Relativní četnost se zadává jako číslo v intervalu [0,1] nebo v procentech.
Například relativní četnost hodnoty „Vanesa“ znaku jméno je \frac{2}{10}=0{,}2, protože ve skupince celkem deseti dětí jsou dvě žákyně jménem Vanesa. Relativní četnost hodnoty „Vanesa“ znaku jméno můžeme zapsat také jako 20\ \%.
Součet absolutních četností všech hodnot jednoho znaku je roven rozsahu n daného statistického souboru.
Součet relativních četností všech hodnot jednoho znaku je 1 neboli 100\ \%.
Rozhodovačka
Rychlé procvičování výběrem ze dvou možností.

Absolutní a relativní četnost (lehké) • FRP
Typicky zabere: 6 min
Absolutní a relativní četnost (střední) • FRL
Typicky zabere: 7 min
Absolutní a relativní četnost (těžké) • G9T
Typicky zabere: 7 min